
m-demare/hlargs.nvim
 github
github
 529
529
 4
4
 4
4
 12
12
hlargs.nvim
Highlight arguments' definitions and usages, asynchronously, using Treesitter.
Optionally, apply special highlighting for unused arguments
Preview
| Before | After |
|---|---|
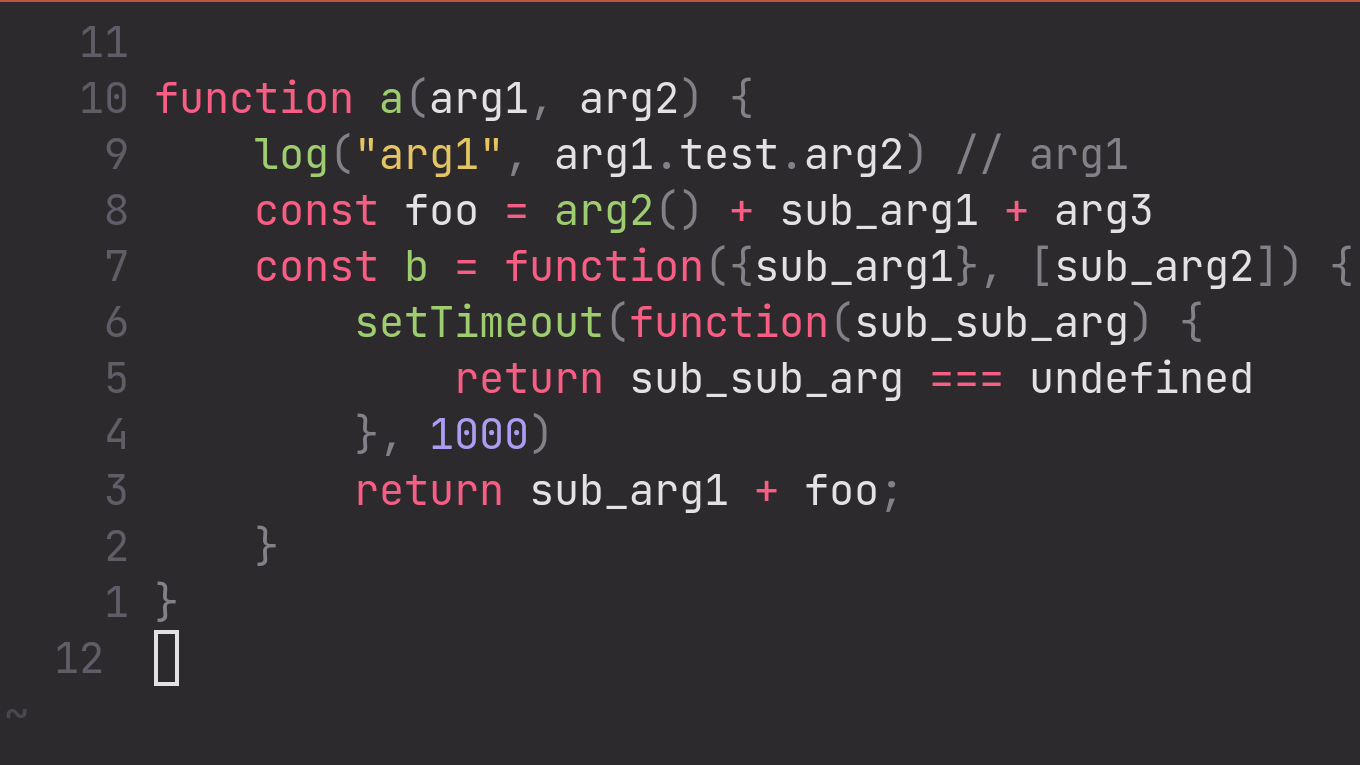 |
 |
hlargs vs LSP semantic tokens
Neovim 0.9 officially added support for LSP semantic tokens. These offer a much more complete and precise form of highlighting than hlargs. These two methods can coexist, for example by using hlargs for the languages where LSP tokens are not available, or they are available but don't define special highlight groups for arguments (check out :h hlargs-lsp for an example).
Some advantages of hlargs are:
- Available in languages without LSP
- Available in languages whose LSP does not support semantic tokens
- Some LSP might not have granular enough tokens to allow for arguments' highlighting
- Treesitter parsers are generally easier to install than LSP servers
- Treesitter parsers have wider platform compatibility than many LSP servers
- Faster startup speed
Installation
This plugin is for neovim only. Version 0.7+ is recommended. If
you are using 0.6, use the branch 0.6-compat and an appropriate nvim-treesitter
version (installation instructions in the README of that branch).
For nvim versions <0.9, nvim-treesitter is a required dependency. For 0.9 or higher, it is not necessary (though it's highly recommended, to install the parsers)
return {
'm-demare/hlargs.nvim',
}
use { 'm-demare/hlargs.nvim' }
Plug 'm-demare/hlargs.nvim'
Usage
If you are ok with the default settings:
require('hlargs').setup()
To change the settings:
require('hlargs').setup {
color = '#ef9062',
highlight = {},
excluded_filetypes = {},
disable = function(lang, bufnr) -- If changed, `excluded_filetypes` will be ignored
return vim.tbl_contains(opts.excluded_filetypes, lang)
end,
paint_arg_declarations = true,
paint_arg_usages = true,
paint_catch_blocks = {
declarations = false,
usages = false
},
extras = {
named_parameters = false,
unused_args = false,
},
hl_priority = 120,
excluded_argnames = {
declarations = {},
usages = {
python = { 'self', 'cls' },
lua = { 'self' }
}
},
performance = {
parse_delay = 1,
slow_parse_delay = 50,
max_iterations = 400,
max_concurrent_partial_parses = 30,
debounce = {
partial_parse = 3,
partial_insert_mode = 100,
total_parse = 700,
slow_parse = 5000
}
}
}
-- (You may omit the settings whose defaults you're ok with)
To understand the performance settings see performance. The other settings should be self explainatory
After setup, the plugin will be enabled. You can enable/disable/toggle it using:
require('hlargs').enable()
require('hlargs').disable()
require('hlargs').toggle()
Dynamically change color
If you want to change the color dynamically, according to filetype or whatever, you can do that using the highlight group Hlargs
Supported languages
Currently these languages are supported
- astro (you need both the
astroparser and the JS/TS one) - c
- cpp
- c_sharp (C#)
- go
- java
- javascript
- jsx (react)
- julia
- kotlin
- lua
- nix
- php
- python
- r
- ruby
- rust
- solidity
- tsx (react)
- typescript
- vim
- zig
Note that you have to install each language's parser using :TSInstall {lang}
jsx parser gets installed with the javascript one, but tsx parser is independent from the
typescript one
Request new language
Please include a sample file with your request, that covers most of the edge cases that specific language allows for (nested functions, lambda functions, member functions, parameter destructuring, optional parameters, rest paratemeters, etc). See examples.
Also do note that I can't support a language that doesn't have a Treesitter parser implemented. Check here
Performance
This plugin uses a combination of incremental and total parsing, to achieve both great speed and consistent highlighting results. It works as follows:
- When a new buffer is opened, or when a file is externally modified, a total parse task is launched. This is CPU intensive, but should rarely happen
- When the buffer is modified, a partial task is launched for every modified group of lines
(identifying the region that should be parsed depending on what was modified), up to
max_concurrent_partial_parses. If this is exceeded (e.g. by a big find and replace), a total parse task is launched. Partial tasks are extremely fast/lightweight, allowing for real time highlighting with barely any CPU impact. However, it is not 100% precise, in some weird edge cases it might miss some usages. Hence, upon every change, with a big debouncing, a "slow" task is launched - Slow tasks are the same as total tasks, except they are throttled on purpose so that they use basically 0 CPU. The idea is that partial tasks are generally very precise, so these just run in the background when needed to fix some of the small imprecisions that might be left
The results of these 3 types of tasks are merged in order to always show the most up to date information
There are a couple of settings that let you adjust performance to your own use case. I recommend only playing with them if you are having some specific issue, otherwise the defaults should work fine
parse_delayis the time between parsing iterations, left for vim to compute other events. Longer means less CPU load, but slower parsing (default: 1ms)slow_parse_delayis the same asparse_delay, but for slow tasks. I should be set in a value such that CPU usage from slow parses is negligible (default: 50ms)max_iterationsis the maximum amount of functions it will parse. The main objective of this is that it doesn't waste too much time parsing huge minified files, but you can set it lower if your PC struggles with smaller files (default: 400)max_concurrent_partial_parsesis the maximum amount of partial parsing tasks allowed. If the limit is exceeded, no more partial tasks will launch, and instead a single total task will be used (default: 30)debounce.partial_parse: the time it waits for new changes before launching the partial tasks for some changes. The idea is that when multiple changes happen in a short amount of time, overlapping changes can be merged into a single task (default: 3ms)debounce.partial_insert_mode: same as previous, but for insert mode. If you don't want real time highlighting in insert mode, you can increase this to 1-2 seconds (default: 100ms)debounce.total_parse: same but for total parses. Rarely used. (default: 700ms)debounce.slow_parse: same but for slow parses. It affects how quickly the highlighting will regain consistency after it is lost, but you shouldn't set it too low, it might have a big impact (default: 5000ms)